Development #65744
Performance: formdata.store va faire un update sur toutes les instances d'evolution
0%
Description
Même sans modification de formdata.evolutions, un update est fait systématiquement sur chaque Evolution lors d'un store sur formdata.
Or un UPDATE, même s'il ne change pas les données, n'est par défaut pas optimisé dans PostgreSQL afin de conserver ses effets de bord.
Étant donné qu'on a plusieurs cas où des milliers, voire des dizaines de milliers d'objets Evolution rattachés à un formdata, on arrive sur notamment l'environnement saas.test à une utilisation en permanence d'un CPU sur le serveur PostgreSQL uniquement pour traiter ces UPDATE en boucle.
Fichiers
Demandes liées
Révisions associées
Historique
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Lié à Development #65745: test.saas: tables __evolutions avec des dizaines de milliers d'entrées par formdata ajouté
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Fichier 0001-sql-don-t-update-when-Evolution-object-is-unchanged-.patch 0001-sql-don-t-update-when-Evolution-object-is-unchanged-.patch ajouté
- Statut changé de Nouveau à Solution proposée
- Patch proposed changé de Non à Oui
Voilà le patch. Il passe les tests unitaires, et a priori devrait réduire la charge sur les PGs. Avec le pgbouncer des machines de test, on le verra facilement.
Mis à jour par Benjamin Dauvergne il y a presque 2 ans
Il me semble que le premier et nouveau Evolution.__init__ est écrasé par le deuxième (j'ai juste regarder le patch vite fait).
Mis à jour par Pierre Ducroquet il y a presque 2 ans
Silly me, comme on dit.
En complément du coup (et ça passe toujours le jenkins)
Mis à jour par Frédéric Péters il y a presque 2 ans
Je n'aime pas trop la multiplication des getter/setter, sur un tas d'attributs qui ne peuvent pas bouger.
Par contre, parts est une liste dont le contenu peut bouger, et le getter/setter va passer à côté de ça.
Je serais pour une approche moins technique et plutôt analyser ce qui peut effectivement bouger sur un objet Evolution (sans regarder je dirais que ça concerne juste last_jump_datetime et le contenu de parts).
Mis à jour par Frédéric Péters il y a presque 2 ans
Je serais pour une approche moins technique et plutôt analyser ce qui peut effectivement bouger sur un objet Evolution (sans regarder je dirais que ça concerne juste last_jump_datetime et le contenu de parts).
Et noter que ce sera toujours le dernier evolution qui sera modifié, jamais les précédents, et peut-être que juste se baser là-dessus serait totalement satisfaisant.
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Fichier 0001-sql-only-the-last-Evolution-object-can-be-changed-65.patch 0001-sql-only-the-last-Evolution-object-can-be-changed-65.patch ajouté
Patch modifié du coup : update uniquement sur la dernière instance de l'objet evolution, et on oublie toute tentative de savoir si les objets ont été modifiés ou non.
Mis à jour par Frédéric Péters il y a presque 2 ans
J'ai l'impression qu'on peut plus simplement :
+ # iterate in reverse order to only save new and last evolution + for evo in reversed(self._evolution): ... - evo._sql_id = cur.fetchone()[0] + if hasattr(evo, '_sql_id'): + break + else: + evo._sql_id = cur.fetchone()[0]
Mis à jour par Pierre Ducroquet il y a presque 2 ans
Frédéric Péters a écrit :
J'ai l'impression qu'on peut plus simplement :
[...]
Moi aussi j'y ai cru... mais dans ce cas les id ne seront plus séquentiels. Je n'ai donc pas voulu casser cette supposition (qui, je crois, est testée dans un test unitaire)
Mis à jour par Frédéric Péters il y a presque 2 ans
Moi aussi j'y ai cru... mais dans ce cas les id ne seront plus séquentiels. Je n'ai donc pas voulu casser cette supposition (qui, je crois, est testée dans un test unitaire)
Ok, ça me semble quelque chose qui mérite d'être changé, je vois hors tests, l'ORDER BY devrait vraiment être adapté.
sql_statement = (
'''SELECT id, who, status, time, last_jump_datetime,
comment, parts FROM %s_evolutions
WHERE formdata_id = %%(id)s
ORDER BY id'''
% self._table_name
)
et peut-être d'autres.
Mis à jour par Pierre Ducroquet il y a presque 2 ans
Le champ time des objets evolution n'est précis (côté python) qu'à la seconde. Du coup en cas d'insertion de plusieurs objets créés sur un intervalle court, on ne pourra pas trier avec ce seul critère, il faudra un autre critère pour les distinguer.
Actuellement, sur la base de test, j'ai trouvé sans difficultés une table evolution où on a deux objets evolutions pour le même formdata et le même time.
Mis à jour par Frédéric Péters il y a presque 2 ans
Ok, on ne se lance pas là-dedans du coup; je serais quand même pour revoir le patch, pas fan du for i in range(len(self._evolution) - 1, -1, -1):, plutôt pour quelque chose type,
for idx, evo in enumerate(self._evolution):
if not hasattr(evo, '_sql_id'):
break
for evo in self._evolution[idx:]:
# le code actuel
(qui ne doit pas être correct, c'est pour l'idée)
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Fichier 0001-sql-only-the-last-Evolution-object-can-be-changed-65.patch 0001-sql-only-the-last-Evolution-object-can-be-changed-65.patch ajouté
Le code me semble correct et passe les tests unitaires.
Mis à jour par Benjamin Dauvergne il y a presque 2 ans
- Statut changé de Solution proposée à Solution validée
Et noter que ce sera toujours le dernier evolution qui sera modifié, jamais les précédents, et peut-être que juste se baser là-dessus serait totalement satisfaisant.
Je ne vois pas dans ce dernier patch ce qui fait que la dernière évolution est toujours sauvegardée, on est certain qu'elle n'a pas de _sql_id ?
Ok on repart de idx idx qui est au maximum len(evo)-1 donc c'est bon. Validé.
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Statut changé de Solution validée à Résolu (à déployer)
Merci ! mergé
commit aebf5a59b50650943b722f86e910f7a75fd824f2 (HEAD -> main, origin/main, origin/HEAD, wip/65744-evolution-needless-update)
Author: Pierre Ducroquet <pducroquet@entrouvert.com>
Date: Mon May 30 08:52:50 2022 +0200
sql: only the last Evolution object can be changed (#65744)
Mis à jour par Transition automatique il y a presque 2 ans
- Statut changé de Résolu (à déployer) à Solution déployée
Mis à jour par Pierre Ducroquet il y a presque 2 ans
- Fichier Screenshot_20220701_005142.png Screenshot_20220701_005142.png ajouté
- Fichier Screenshot_20220701_005240.png Screenshot_20220701_005240.png ajouté
On voit nettement le déploiement...
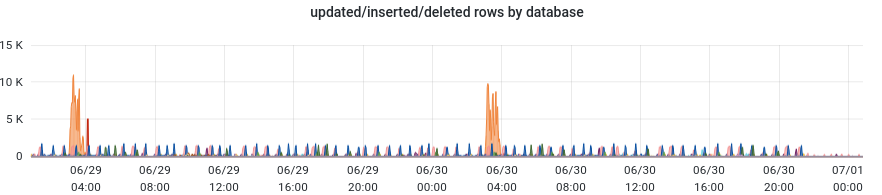
Si on zoome sur les 12 dernières heures...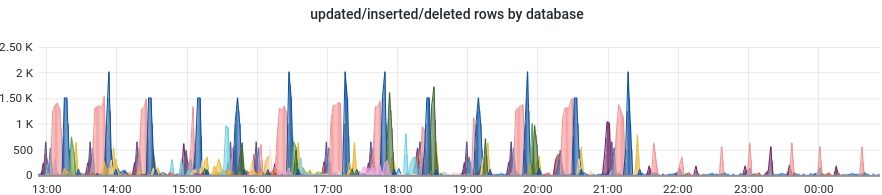
J'ai hâte de voir le résultat sur les WAL et le bloat...
Mis à jour par Pierre Ducroquet il y a presque 2 ans
Sur une semaine, le volume de WAL a été divisé par deux en recette.
sql: only the last Evolution object can be changed (#65744)