Development #9416
endpoint /check (ou autre) pour vérif minimale du bon fonctionnement du service distant
0%
Description
On a pour certains connecteurs un /ping, qui vérifie un appel simple au service distant. Je pense qu'il faudrait généraliser et standardiser ça, qu'on puisse ensuite balancer un check_http nagios dessus, pour obtenir gratuitement l'info de downtime de ces services.
Fichiers
{kind=link}
Révisions associées
tests: add tests for availability parts (#9416)
Historique
Mis à jour par Thomas Noël il y a plus de 8 ans
Moi j'aime bien /ping.
JSON de la réponse "tout va bien":
{
"data": {
"ping": "pong"
},
"err": 0
}
Mis à jour par Frédéric Péters il y a presque 8 ans
Je pense que dans le travail de factorisation actuel, ça serait pas mal de faire revivre cette demande, d'un endpoint ping/check généralisé. Je me dis aussi que même sans nagios, on pourrait avoir en interne dans passerelle un système de suivi de disponibilité; qui au-délà du ping/check pourrait être alimenté par les appels réussis/ratés (genre quand un appel distant échoue on appelle le code ping/check pour faire la part des choses entre un bug de l'appel et une indisponibilité du système distant, et on en profite pour enregistrer l'info).
Mis à jour par Frédéric Péters il y a plus de 7 ans
Basiquement ça pourrait être un bloc supplémentaire affiché sur la page du connecteur, avec les dernières indisponibilités :
- down le 27 septembre 2016 de 10h04 à 10h32
- etc.
Mis à jour par Frédéric Péters il y a plus de 7 ans
Il y a différentes parties :
- Avoir dans tous les connecteurs (qui fonctionnent avec une appli distante) une fonction minimale de vérification de bon fonctionnement de celle-ci; par exemple dans le connecteur Agora+ il y a un appel qui demande juste un token; dans le connecteur base adresse il pourrait y avoir un appel vers "http://api-adresse.data.gouv.fr/search/?q=169%20rue%20du%20chateau,%20paris&limit=1" et vérification du résultat, dans le connecteur gdc récupération de la liste des communes, etc. Le seul truc important c'est que ça n'ait pas d'effet de bord, on ne va pas créer de fausses demandes pour vérifier le bon fonctionnement. Pour commencer ici, il est bien sûr suffisant de juste assurer ça pour un ou deux connecteurs, pas besoin de tous les faire. base_adresse et gdc sont de bons candidats dans la mesure où ils sont déjà plutôt nouveau style.
- Il faut un modèle global, qui contiendrait au moins la référence vers un connecteur, un timestamp de début d'indispo, un timestamp de fin d'indispo.
- Une commande de management, qui sera lancée par un cron, qui pose un lock et appelle pour tous les connecteurs la méthode de vérif, comme il va surtout y avoir de la latence réseau, ils peuvent être lancés en tas en parallèle; qui ajoute une ligne en cas de nouvelle erreur (et pose le timestamp de fin d'indispo si pas d'erreur).
- L'ajout d'un bloc "Indisponibilités récentes" dans le template service_view.html (affiché uniquement aux personnes qui ont perms.base.view_accessright, je dirais)
Et en fait ça peut très bien s'arrêter à ça.
À la suite, dans BaseResource, on peut ajouter un endpoint ping, qui appelle la fonction ajoutée au-dessus, mais ce n'est même pas important.
Aussi, ce qu'il pourrait y avoir en plus, c'est dans GenericEndpointView de quoi automatiquement appeler le check en cas d'erreur, pour identifier l'indisponibilité dès la première erreur (et dans l'autre sens, en cas d'appel réussi alors que le service est marqué indispo, marquer que c'est revenu).
Peut-être, quand le service distant est marqué comme indisponible, imaginer que GenericEndpointView réponde plutôt par lui-même que le service est indispo, que le code du connecteur ne soit même pas appelé.
À voir aussi, faire en sorte que la fréquence de vérification augmente lors des périodes d'indisponibilités (genre ce serait toutes les dix minutes quand tout va a priori bien et toutes les minutes pour les connecteurs se déclarant en indispo).
En terme de vues, ensuite, un tas de trucs sont possibles aussi, afficher un graphe et/ou des stats de disponibilité (comme nagios, ex: https://eudat.eu/sites/default/files/pictures/eudat3.png).
{kind=link}
À parler de nagios aussi, avoir une vue http /check générale, qui réponde simplement ok quand tous les services sont ok, et une erreur quand ce n'est pas le cas. (on n'est vraiment pas équipé pour le moment pour suivre dans nagios les connecteurs un par un, mais un check par passerelle, ça doit se faire).
Bref, pour ce ticket j'en resterais aux premiers points, le reste ça peut être des idées pour des tickets supplémentaires, après.
Mis à jour par Jean-Baptiste Jaillet il y a plus de 7 ans
- Fichier 0001-endpoints-add-check-for-base_adresse-endpoint-9416.patch 0001-endpoints-add-check-for-base_adresse-endpoint-9416.patch ajouté
Voilà. J'ai fait quelque chose pour base_adresse.
Je pose un patch maintenant pour savoir si c'est la bonne direction, et prendre maintenant les critiques pour le caler après pour gdc aussi.
Mis à jour par Jean-Baptiste Jaillet il y a plus de 7 ans
je pense notamment à la requête envoyée pour tester le service.
Peut être faire (au lieu de juste != 200) un test si c'est 400 (indisponible) ou 500 (le serveur a merdé soit à cause de ce qu'on envoie, soit parce que le serveur fait de la merde)
Mis à jour par Jean-Baptiste Jaillet il y a plus de 7 ans
enfin pour 400 indisponible ou l'adresse du service n'est plus à jour.
Mis à jour par Frédéric Péters il y a plus de 7 ans
Les connecteurs en eux-mêmes ne doivent rien savoir de la classe EndpointCheckPing (qui parait s'appeler ServiceAvailabityReport, genre).
Dans le connecteur, la méthode elle doit juste vérifier la disponibilité et retourner vrai ou faux.
def availability_check(self):
scheme, netloc, path, params, query, fragment = urlparse.urlparse(self.service_url)
path = '/search/'
query = urlencode({'q': 'rue du chateau', 'limit': 1})
url = urlparse.urlunparse((scheme, netloc, path, params, query, fragment))
result_response = self.requests.get(url)
return len(result_response.json().get('features')) > 0
connector = models.CharField(max_length=50, verbose_name='Connector\'s slug')
Faut passer par ContentType, comme c'est fait dans le modèle AccessRight.
Mis à jour par Jean-Baptiste Jaillet il y a plus de 7 ans
D'accord.
Du coup comment le modèle se met à jour (celui qui garde en base les derniers couacs debut / fin) ?
Il instancie un connecteur (paramètre du modèle) et lance la fonction availability?
Mis à jour par Frédéric Péters il y a plus de 7 ans
→ Une commande de management, qui sera lancée par un cron, qui pose un lock et appelle pour tous les connecteurs la méthode de vérif [...]
cf la page d'accueil pour lister l'ensemble des connecteurs définis.
Mis à jour par Frédéric Péters il y a plus de 6 ans
- Fichier availability.png availability.png ajouté
- Fichier 0001-general-add-service-availability-basics-9416.patch 0001-general-add-service-availability-basics-9416.patch ajouté
- Statut changé de Nouveau à En cours
- Assigné à mis à Frédéric Péters
- Patch proposed changé de Non à Oui
Reprise à zéro.
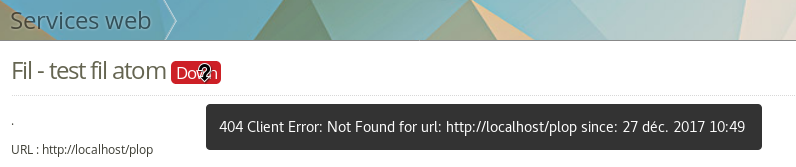
Ajout d'un suivi de la disponibilité d'un service, cron exécuté toutes les cinq minutes; pour le moment simplement utilisé pour afficher "down" sur la page du connecteur quand c'est le cas. Tests ajoutés aux connecteurs base adresse, fil atom/rss et opengis. (il s'agit simplement de poser une méthode qui lèvera une exception en cas d'erreur).
En perspective reprendre l'information sur la page d'accueil, avoir une vue détaillée du taux de disponibilité, intégrer à la gestion des erreurs (si un endpoint échoue, appeler le test de dispo pour voir dès ce moment si c'est pas juste tout le service qui est down, etc.). Tout cela dans de futurs tickets une fois l'infra en place.
Mis à jour par Thomas Noël il y a plus de 6 ans
Je pense qu'on devrait lancer un self.availability() lors du save, car j'imagine le cas du service qui est "down" parce que l'URL est erronée, et on la modifie, mais il faut attendre 5 minutes avant que ça revienne (ou pas). Avec une vérification lors de la création/modification d'un connecteur, on éviterait ce cas (et on proposerait une technique pour "forcer" un check, pas trop cachée mais un peu quand même)
Mis à jour par Frédéric Péters il y a plus de 6 ans
- Fichier 0001-general-add-service-availability-basics-9416.patch 0001-general-add-service-availability-basics-9416.patch ajouté
J'ai préféré dupliquer ça au niveau des vues de création et d'édition, plutôt que faire ça dans le .save(), pour ne pas qu'une commande genre import_site se trouve aussi emmener toutes ces vérifications. (mais ça peut se discuter)
Mis à jour par Thomas Noël il y a plus de 6 ans
Ça me va très bien, je n'aime pas trop les save surchargés, effets de bord effectivement à craindre.
Au niveau de l'utilisation dans le template :
{% with status=object.get_availabity_status %}
{% if status.down %}<span class="down" title="{{status.message}} {% trans 'since:' %} {{status.start_timestamp|date:"SHORT_DATETIME_FORMAT"}} ">{% trans 'Down' %}</span>{% endif %}
{% endwith %}
j'aimerai bien que tu ajoutes un if status qui rappelle qu'il n'y a pas forcément de status, soit parce qu'il n'a pas encore encore été joué après un import, soit parce que le connecteur n'a pas de testeur (c'est vraiment juste pour s'en rappeler, la lecture du code est assez explicite)
Et à penser à ça, est-ce qu'on ajouterait pas l'info "OK" quand status.up (et donc, on enregistrait la date du dernier succès dans le availability()) ?
Sauf si tu as des idées sur ces points là, c'est déjà un ack ainsi -- on pourra faire évoluer cette base à l'usage.
Mis à jour par Frédéric Péters il y a plus de 6 ans
- Statut changé de En cours à Résolu (à déployer)
j'aimerais bien que tu ajoutes un if status qui rappelle qu'il n'y a pas forcément de status, soit parce qu'il n'a pas encore encore été joué après un import, soit parce que le connecteur n'a pas de testeur (c'est vraiment juste pour s'en rappeler, la lecture du code est assez explicite)
Ajouté.
Et à penser à ça, est-ce qu'on ajouterait pas l'info "OK" quand status.up
Je suis en fait encore hésitant, dans un premier temps je resterais à "down = on est sûr en face que c'est mort" et rien afficher autrement. Cela étant dans #20901 je me contredis déjà en affichant une marque sur la page d'accueil quand le service apparait comme disponible (mais je pense que je devrais la retirer).
(et donc, on enregistrait la date du dernier succès dans le availability()) ?
Ça pourrait facilement évoluer pour enregistrer la date de dernière vérification mais ça me va bien pour le moment d'écrire dans la db uniquement en cas de changement.
Sauf si tu as des idées sur ces points là, c'est déjà un ack ainsi -- on pourra faire évoluer cette base à l'usage.
Je pousse ainsi et clairement ça pourra évoluer.
commit 840693f81972838ffd5f8627c04bc3b0791c1cb9
Author: Frédéric Péters <fpeters@entrouvert.com>
Date: Wed Dec 27 11:17:20 2017 +0100
general: add service availability basics (#9416)
Mis à jour par Frédéric Péters il y a plus de 6 ans
Et du commit j'avais oublié le fichier avec les tests; commit séparé :
commit 1d84c51fb10a9efa8de903ec331e1a2ed8647e31
Author: Frédéric Péters <fpeters@entrouvert.com>
Date: Tue Jan 2 08:58:16 2018 +0100
tests: add tests for availability parts (#9416)
Mis à jour par Benjamin Dauvergne il y a plus de 5 ans
- Statut changé de Résolu (à déployer) à Fermé
general: add service availability basics (#9416)