Development #5896
créer un connecteur "nouveau style" pour datasource depuis un fichier CSV
0%
Description
Reprendre le datasource CSV actuelle (éventuellement un peu from scratch, depuis un baseresource) et lui donner une nouvelle interface, dont l'édition permettrait de mettre à jour le fichier CSV.
La cible : fournir une liste de {id,text} pour wcs.
On doit fournir pour créer la ressource :
- un csv
- le rang de la colonne qui indique la clé (id) -- 0 par défaut
- le rang de la colonne qui indique le contenu (text) -- 1 par défaut
Lors de l'interrogation, un "?q=abc" renvoie uniquement les lignes qui contiennent "abc" dans le texte.
Options :- permettre de surcharger ces rangs dans la querystring d'interrogation du webservice, genre
id_row=0&text_row=3. - text_rows=2,3,4 où le texte serait un ' '.join() des colonnes indiquées
- indiquer l'url d'un fichier CSV (qui serait mis en cache, durée du cache paramétrable...)
(note: c'est indirectement une demande cg14 pour la mise à jour du csv de dispatch APA, CSV qui sert aussi de base pour les codes postaux)
Fichiers
{kind=link}
Révisions associées
csv files datasource localizations (#5896)
Historique
Mis à jour par Frédéric Péters il y a presque 9 ans
+ la possibilité de nommer les autres colonnes du CSV, pour utilisation en mode "étendu" de wcs.
Mis à jour par Serghei Mihai il y a presque 9 ans
- Assigné à changé de Thomas Noël à Serghei Mihai
Mis à jour par Serghei Mihai il y a presque 9 ans
- Fichier 0001-csv-files-data-source-5896.patch 0001-csv-files-data-source-5896.patch ajouté
- Statut changé de Nouveau à En cours
- Patch proposed changé de Non à Oui
Un patch brouillon.
Ça ne gére pas un csv distant et il manque les tests
Mis à jour par Frédéric Péters il y a presque 9 ans
+ la possibilité de nommer les autres colonnes du CSV, pour utilisation en mode "étendu" de wcs.
Je voyais ça dans la définition, pas lors de l'appel.
Mis à jour par Frédéric Péters il y a presque 9 ans
Aussi, je ne mettrais pas ce module dans contrib.
Mis à jour par Thomas Noël il y a presque 9 ans
Frédéric Péters a écrit :
+ la possibilité de nommer les autres colonnes du CSV, pour utilisation en mode "étendu" de wcs.
Je voyais ça dans la définition, pas lors de l'appel.
Pareil. Peut-être une simple ligne : nom,nom,nom,nom ? (pour faire vite et ne pas avoir une UI tordue)
Mis à jour par Serghei Mihai il y a presque 9 ans
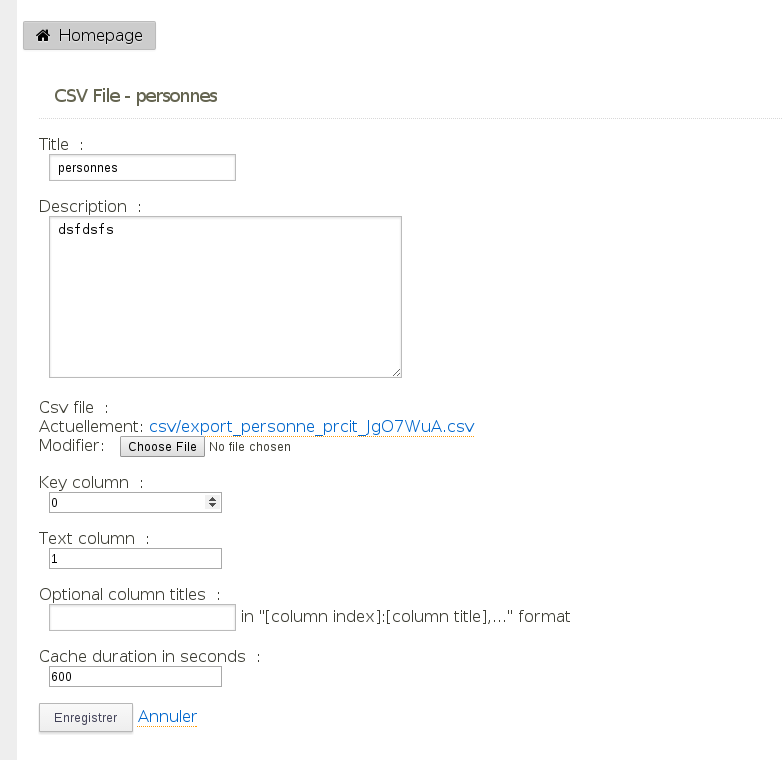
- Fichier csvdatasource.png csvdatasource.png ajouté
- Fichier 0001-csv-files-data-source-5896.patch 0001-csv-files-data-source-5896.patch ajouté
Perso nom, nom, nom ne me parait pas très clair à l'usage, sauf si on y ajoute des help_text.
Voici l'exemple d'une UI avec un champs séparé pour les titres des colonnes
Mis à jour par Serghei Mihai il y a presque 9 ans
Thomas Noël a écrit :
Pareil. Peut-être une simple ligne : nom,nom,nom,nom ? (pour faire vite et ne pas avoir une UI tordue)
Ok, et dans ce cas, la recherche q=abc ne s'appliquera que si la colonne "text" est définie.
Mis à jour par Thomas Noël il y a presque 9 ans
Je disais à l'instant à Serghei : pas de cache explicite du fichier CSV, comptons sur l'OS pour ça.
Mis à jour par Frédéric Péters il y a presque 9 ans
Oui oui, le cache c'était dans la situation d'un CSV distant (« indiquer l'url d'un fichier CSV (qui serait mis en cache, durée du cache paramétrable...) »).
Mis à jour par Thomas Noël il y a plus de 8 ans
- Priorité changé de Normal à Haut
(ça commence à bien manquer, notamment au ministère)
Mis à jour par Serghei Mihai il y a plus de 8 ans
Mis à jour par Frédéric Péters il y a plus de 8 ans
Je suis plutôt favorable à avoir un .po unique à Passerelle.
Pour la logique de columns_title. quand c'est mis, ok, on s'en sert, et quand c'est pas mis, on utilise la première ligne du CSV. J'ai l'impression que dans la pratique, ça va surtout nous ennuyer parce qu'on aura des CSV avec des titres de colonne en première ligne mais pas avec les titres qu'on veut (id, text).
# Create your tests here.
Fichier à supprimer; mais ce serait par contre super d'ajouter des tests dans un tests/test_csv_datasource.py.
Je me demande si on ne gagnerait pas à ne pas mélanger CSV local et CSV distant.
cache.set(self.slug, je préférerais qu'on utilise un hash de l'URL plutôt que permettre via le web d'altérer n'importe quel contenu du cache.
Le filtre, on pourra voir plus tard pour le faire évoluer.
Mis à jour par Serghei Mihai il y a plus de 8 ans
Frédéric Péters a écrit :
Je suis plutôt favorable à avoir un .po unique à Passerelle.
D'accord, j'ai fait un ticket séparé: #8121.
Mis à jour par Thomas Noël il y a plus de 8 ans
Frédéric Péters a écrit :
Il fallait faire un choix, je pense savoir guidé Serghei sur celui-ci. On peut en faire un autre, par exemple:Pour la logique de columns_title. quand c'est mis, ok, on s'en sert, et quand c'est pas mis, on utilise la première ligne du CSV. J'ai l'impression que dans la pratique, ça va surtout nous ennuyer parce qu'on aura des CSV avec des titres de colonne en première ligne mais pas avec les titres qu'on veut (id, text).
- une case à cocher qui indique si la première colonne est un titre, et génère des slug à partir de ça ("nom du village" -> "nom-du-village")
- dans ce cas, si columns_title existe, elle "écrase" le nom de certaines colonne : «
,,id,,,text» dit que "id" est dans la colonne 3 et text dans la 6ème.
Je me demande si on ne gagnerait pas à ne pas mélanger CSV local et CSV distant.
Oui, ça ferait un code beaucoup plus clair (on n'a pour l'instant pas besoin du principe des CSV distants)
Le filtre, on pourra voir plus tard pour le faire évoluer.
Oui, par rapport à http://git.entrouvert.org/passerelle.git/tree/passerelle/datasources/models.py on a quand même des regressions, je trouve (possibilité de choisir la/les colonne à considérer comme résultat, c'est utile pour le dispatch cg14 par exemple)
Mais on peut pousser une version simple et jouer ensuite.
Mis à jour par Frédéric Péters il y a plus de 8 ans
Thomas Noël a écrit :
Frédéric Péters a écrit :
Il fallait faire un choix, je pense savoir guidé Serghei sur celui-ci. On peut en faire un autre, par exemple:Pour la logique de columns_title. quand c'est mis, ok, on s'en sert, et quand c'est pas mis, on utilise la première ligne du CSV. J'ai l'impression que dans la pratique, ça va surtout nous ennuyer parce qu'on aura des CSV avec des titres de colonne en première ligne mais pas avec les titres qu'on veut (id, text).
- une case à cocher qui indique si la première colonne est un titre, et génère des slug à partir de ça ("nom du village" -> "nom-du-village")
- dans ce cas, si columns_title existe, elle "écrase" le nom de certaines colonne : «
,,id,,,text» dit que "id" est dans la colonne 3 et text dans la 6ème.
Oui, je trouve plutôt important de pouvoir zapper la première ligne.
Je me demande si on ne gagnerait pas à ne pas mélanger CSV local et CSV distant.
Oui, ça ferait un code beaucoup plus clair (on n'a pour l'instant pas besoin du principe des CSV distants)
Si on n'en a pas besoin, alors, pour moi, on peut tout à fait zapper cette partie pour l'instant et avoir du code plus simple.
Mis à jour par Serghei Mihai il y a plus de 8 ans
Frédéric Péters a écrit :
Oui, je trouve plutôt important de pouvoir zapper la première ligne.
Pareil.
Et je rendrais columns_title obligatoire au format «,,id,,,text», comme sugère Thomas.
Mis à jour par Serghei Mihai il y a plus de 8 ans
Avec des tests
Mis à jour par Frédéric Péters il y a plus de 8 ans
Il n'y a plus besoin de CACHE_SENTINEL.
Le patch zappe désormais systématiquement la première ligne, ce n'est pas souhaité. (le test passe à côté de ça en commançant le csv par une ligne vide).
Mis à jour par Serghei Mihai il y a plus de 8 ans
Avec un flag pour zapper l'entete
Mis à jour par Frédéric Péters il y a plus de 8 ans
titles = self.columns_titles.split(',')
indexes = [titles.index(t) for t in titles if t.split()]
caption = [titles[i] for i in indexes]
Il y a ce if t.split() qui m'interloque; c'est quoi son rôle ?
columns_titles='id,,nom, prenom, sexe'
Avec une définition pareille, les noms de colonne vont garder les espaces, ça ne fera pas un truc facilement exploitable; ce serait bien que ça soit aussi testé par les tests.
Dans les tests aussi, en plus de vérifier que les dictionnaires ont les bonnes clés, ça peut être utile d'en vérifier aussi les valeurs (genre assert csv.get_data()[0] == {'id': '69', 'text': 'DELANOUE'}).
Dans les données de test il y a parfois des points-virgules parfois des virgules (?).
Mis à jour par Serghei Mihai il y a plus de 8 ans
Ça devait être un strip, je me suis planté.
J'ai rajouté quelques tests en plus, enlevé les virgules(qui viennent d'un export Excel en CSV)
Mis à jour par Frédéric Péters il y a plus de 8 ans
Il manque l'appel à gettext :
class Meta:
verbose_name = 'CSV File'
Et je mettrais les modifs au .po dans un commit séparé.
Il reste des références local_csv_file et remote_csv_file dans le template.
Mis à jour par Frédéric Péters il y a plus de 8 ans
Aussi le columns_titles le "titles" m'ennuie parce qu'on y attend plutôt des identifiants (je suggère column_keynames à la place), et dans le help_text ne pas y mettre des crochets parce qu'on va se demander si on doit les taper (et je remplacerais peut-être juste par un exemple tout bête "ex: id,text,data1,data2").
Mis à jour par Serghei Mihai il y a plus de 8 ans
- Fichier 0001-csv-files-datasource-5896.patch ajouté
ça me va
Mis à jour par Serghei Mihai il y a plus de 8 ans
- Fichier
0001-csv-files-datasource-5896.patchsupprimé
Mis à jour par Serghei Mihai il y a plus de 8 ans
- Fichier 0001-csv-files-datasource-5896.patch 0001-csv-files-datasource-5896.patch ajouté
- Fichier 0002-csv-files-datasource-localizations-5896.patch 0002-csv-files-datasource-localizations-5896.patch ajouté
Et les traductions séparées
Mis à jour par Frédéric Péters il y a plus de 8 ans
Dernier truc j'espère, il reste un bout pas traduit; a priori ça pourrait être {{view.model.get_verbose_name}} :
<h2>CSV - {{ object.title }}</h2>
Mis à jour par Serghei Mihai il y a plus de 8 ans
J'avais fait comme dans nos autres connecteurs:
{% block appbar %}
<h2>GDC - {{ object.title }}</h2>
...
ou
{% block appbar %}
<h2>ClicRdv - {{ object.title }}</h2>
...
Mis à jour par Frédéric Péters il y a plus de 8 ans
Certes, mais d'un côté on a des marques ou noms de produit et ici on a un nom générique.
Mis à jour par Serghei Mihai il y a plus de 8 ans
Alors pour le get_verbose_name
Mis à jour par Serghei Mihai il y a plus de 8 ans
- Statut changé de En cours à Résolu (à déployer)
commit b7239949eaaf5a46ccf919846263562d8ac87767
Author: Serghei Mihai <smihai@entrouvert.com>
Date: Fri Sep 4 11:20:36 2015 +0200
csv files datasource localizations (#5896)
commit a017827f45bf90343dfdfe7d3fa0cc8678fc21f7
Author: Serghei Mihai <smihai@entrouvert.com>
Date: Wed Aug 26 15:39:01 2015 +0200
csv files datasource (#5896)
csv files datasource (#5896)